RLHF: Reinforcement Learning from Human Feedback
article
advanced
Technical Deep Dive
30 min
About This Resource
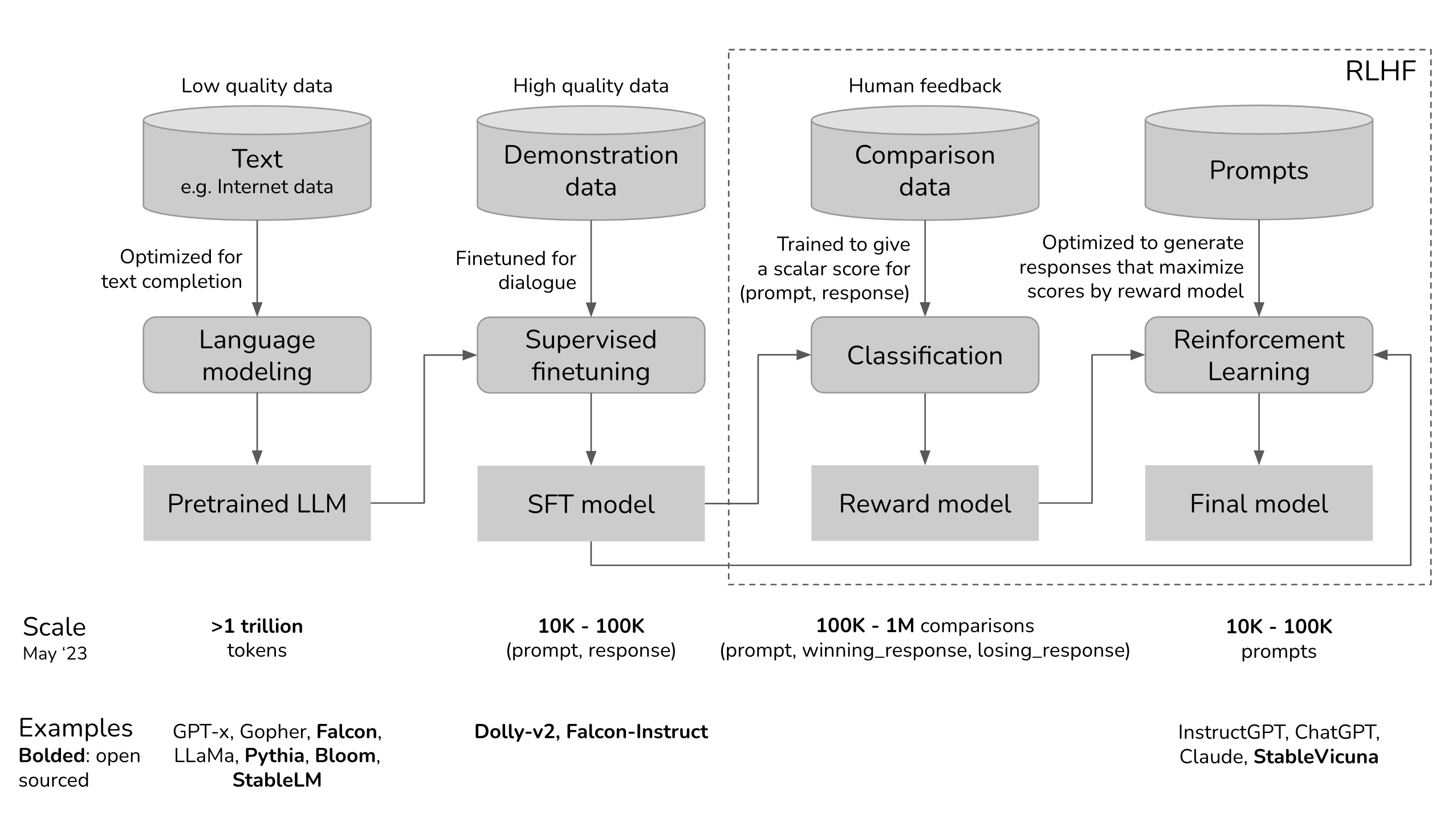
Explanation of RLHF and how it makes large language models more predictable and aligned with human preferences.
Author:Chip Huyen
Source:Chip Huyen Blog
Learn with AI
Get personalized help understanding this resource from leading AI assistants
Explain It Simply
Tutor Mode
Test My Understanding
Click any AI assistant to open it with a pre-filled learning prompt. You can edit before sending.
Sign in to track your progress and mark this resource as completed.